概要
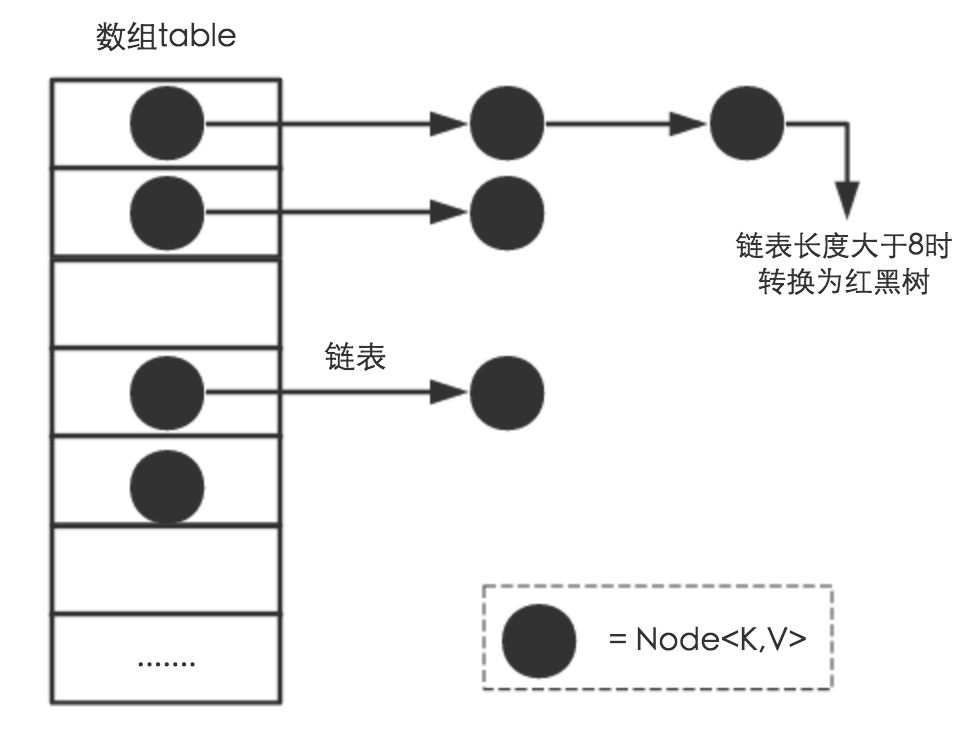
HashMap 是一个关联数组、哈希表,它是线程不安全的,允许key为null,value为null。遍历时无序。 其底层数据结构是数组称之为哈希桶,每个桶里面放的是链表,链表中的每个节点,就是哈希表中的每个元素。 在JDK8中,当链表长度达到8,会转化成红黑树,以提升它的查询、插入效率,它实现了Map<K,V>, Cloneable, Serializable接口。
数据结构
构造方法
1 | //最大容量 2的30次方 |
Node<K,V>
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
扩容
当HashMap的容量达到threshold域值时,就会触发扩容。扩容前后,哈希桶的长度一定会是2的次方。扩容操作时,会new一个新的Node数组作为哈希桶,然后将原哈希表中的所有数据(Node节点)移动到新的哈希桶中,相当于对原哈希表中所有的数据重新做了一个put操作。所以性能消耗很大,可想而知,在哈希表的容量越大时,性能消耗越明显。
1 | final Node<K,V>[] resize() { |
putValue
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
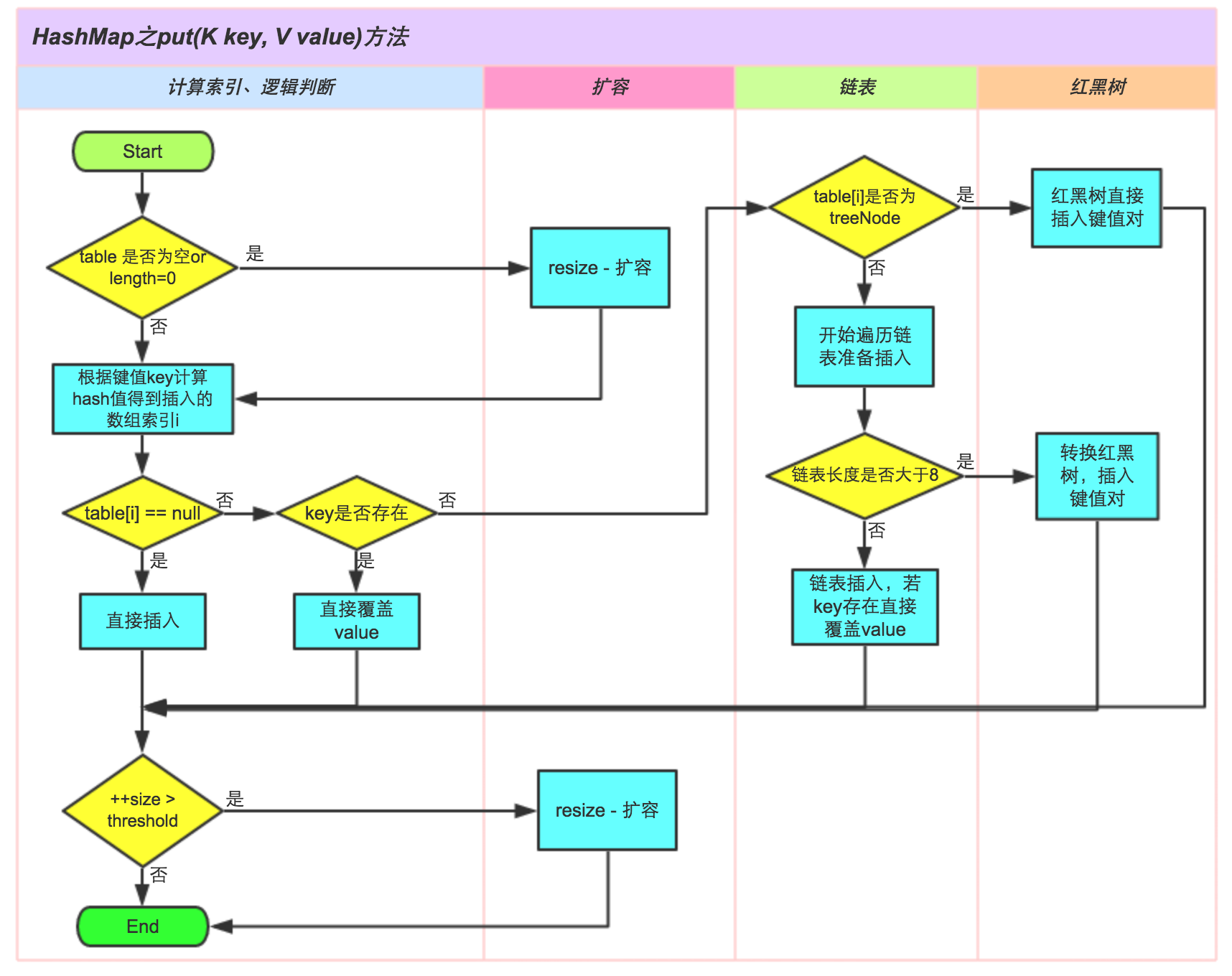
小结
- 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
- 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
- HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
- 红黑树大程度优化了HashMap的性能。