RingBuffer
RingBuffer,即环形的缓冲区。RingBuffer底层是使用数组结构实现的,因为数组对处理器的缓存机制更加友好。同时,为了避免垃圾回收,在数组初始化后就创建event填充数组。
指针偏移
RingBuffer拥有一个序号,这个序号指向数组中下一个可用的元素。随着你不停地填充这个buffer,这个序号会一直增长,直到绕过这个环。所以,必须根据序号来确定元素在数组中的位置。
取模
取模是最简单最常用的方法。通过序号对数组长度取模来确定元素在数组中的位置。
1 | index = sequence mod array.length |
例如:数组长度为8,序号为12,则元素位于12 % 8 = 4。
位运算
disruptor中则使用了更高效的方式计算,位运算。RingBuffer中的素质数组长度必须为2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
1 | index = sequence & (array.length - 1) |
例如:数组长度为8,序号为12,则元素位于12 & (8 - 1) = 4。
Sequence
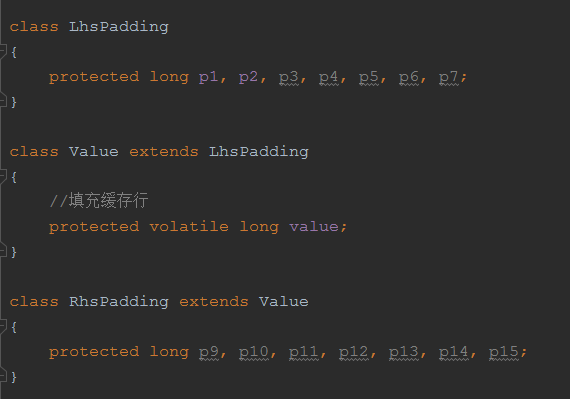
Sequence是RingBuffer中的指针序号类,通过顺序递增的序号来编号管理通过其进行交换的数据。使用被volatile修饰的long值来记录序号。通过CAS操作来保证并发。并通过填充缓存行来提供性能,防止伪共享。关于CPU缓存行及伪共享,请阅读CPU缓存文章。
Sequencer
Sequencer是Disruptor 的真正核心。此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。其巧妙的无锁设计,是Disruptor高性能的关键。
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。整个过程通过原子变量CAS,保证操作的线程安全。
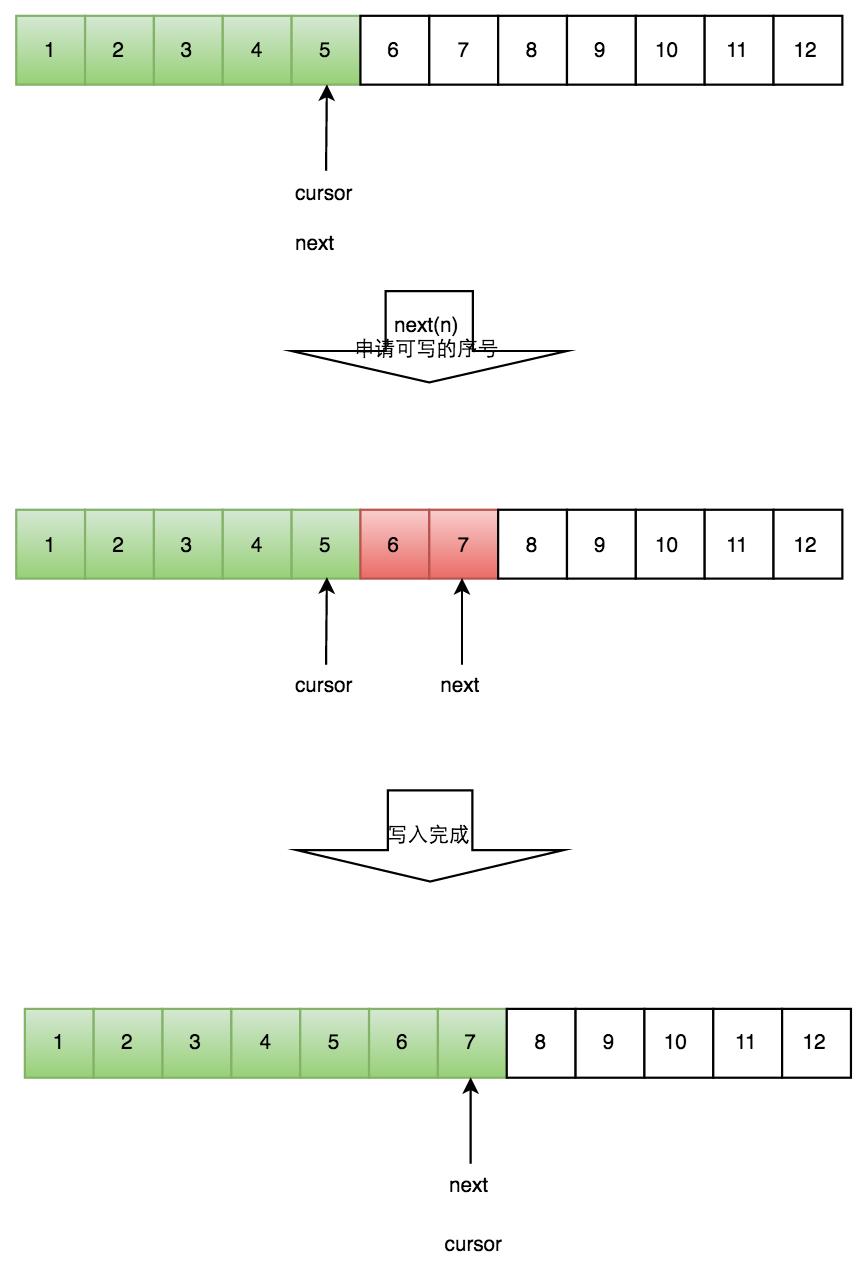
一个生产者
写数据
生产者单线程写数据的流程比较简单:
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素;
- 若是返回的正确,则生产者开始写入元素。
多个生产者
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:available Buffer。当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
读数据
生产者多线程写入的情况会复杂很多:
- 申请读取到序号n;
- 若writer cursor >= n,这时仍然无法确定连续可读的最大下标。从reader cursor开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。
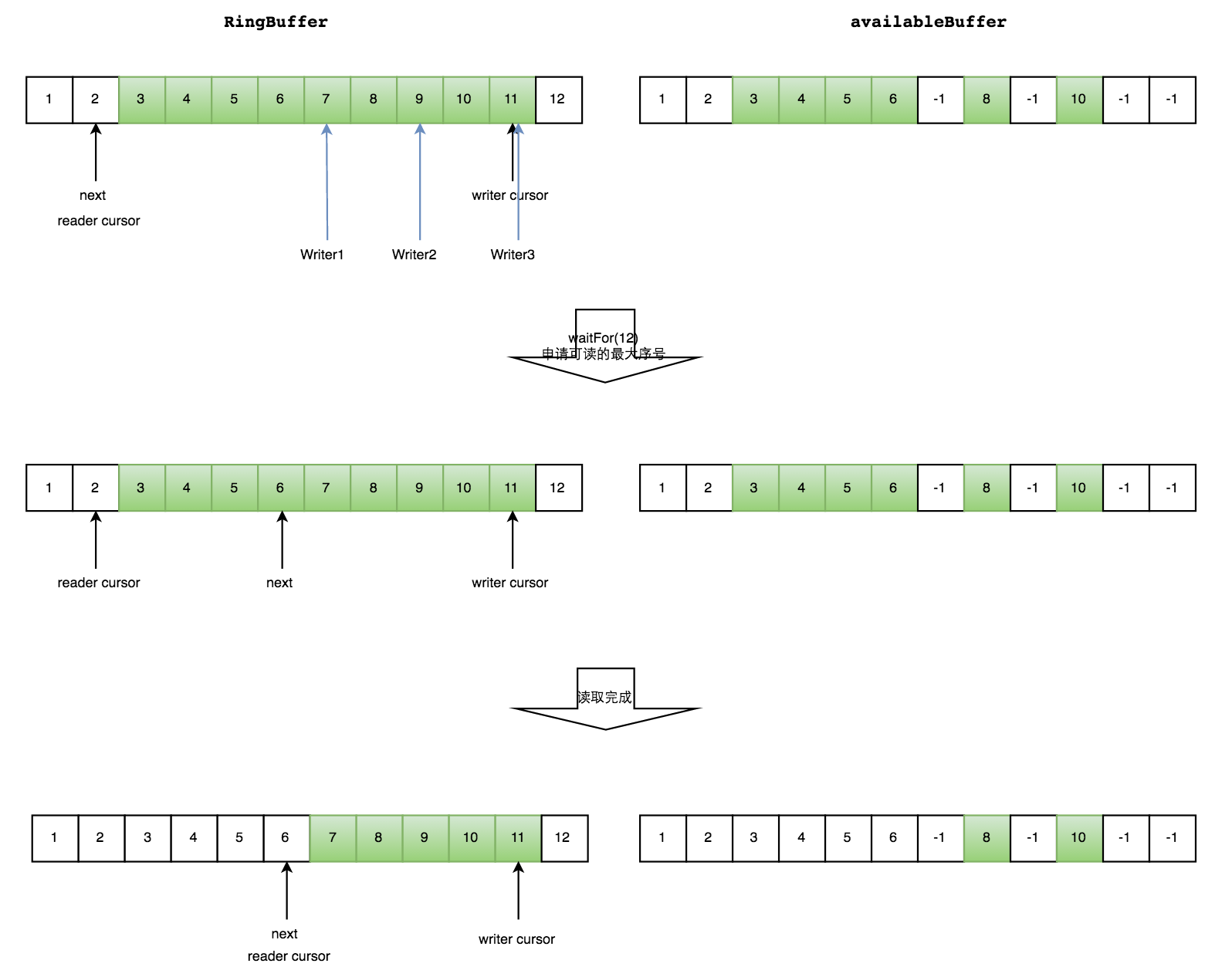
如下图所示,读线程读到下标为2的元素,三个线程Writer1/Writer2/Writer3正在向RingBuffer相应位置写数据,写线程被分配到的最大元素下标是11。
读线程申请读取到下标从3到11的元素,判断writer cursor>=11。然后开始读取availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从3到6共计4个元素。
写数据
多个生产者写入的时候:
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。
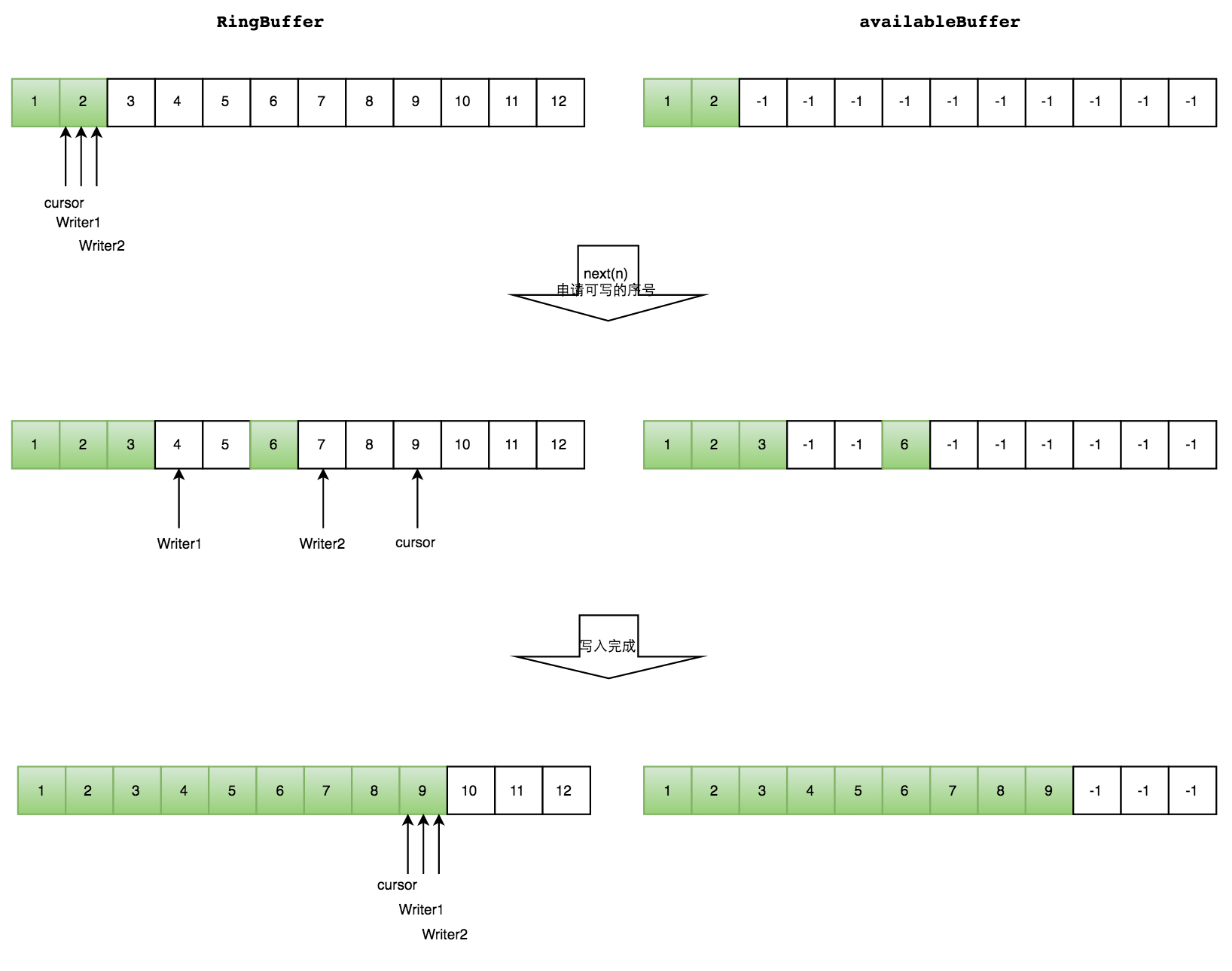
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。
Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。
WaitStrategy
定义Consumer如何进行等待下一个事件的策略。
| 名称 | 措施 | 适用场景 |
|---|---|---|
| BlockingWaitStrategy | 加锁 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| BusySpinWaitStrategy | 自旋 | 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定义策略 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| SleepingWaitStrategy | 自旋 + yield + sleep | 性能和CPU资源之间有很好的折中。延迟不均匀 |
| TimeoutBlockingWaitStrategy | 加锁,有超时限制 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| YieldingWaitStrategy | 自旋 + yield + 自旋 | 性能和CPU资源之间有很好的折中。延迟比较均匀 |
使用样例
1 | public class DisruptorDemo |